GCS → Voyage AI → Qdrant Batch Image Embeddings & Vector Ingest
GCS → Voyage AI → Qdrant Batch Image Embeddings & Vector Ingest
Couldn't load pickup availability
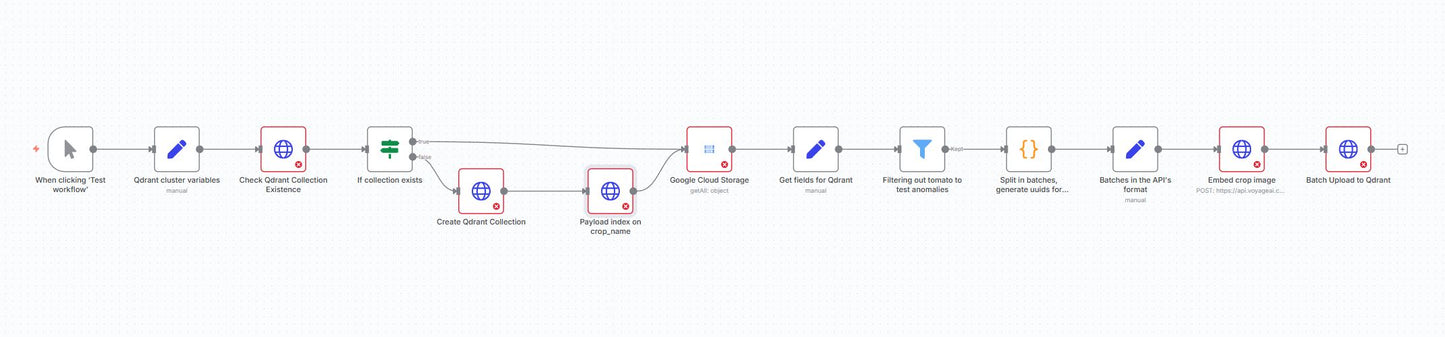
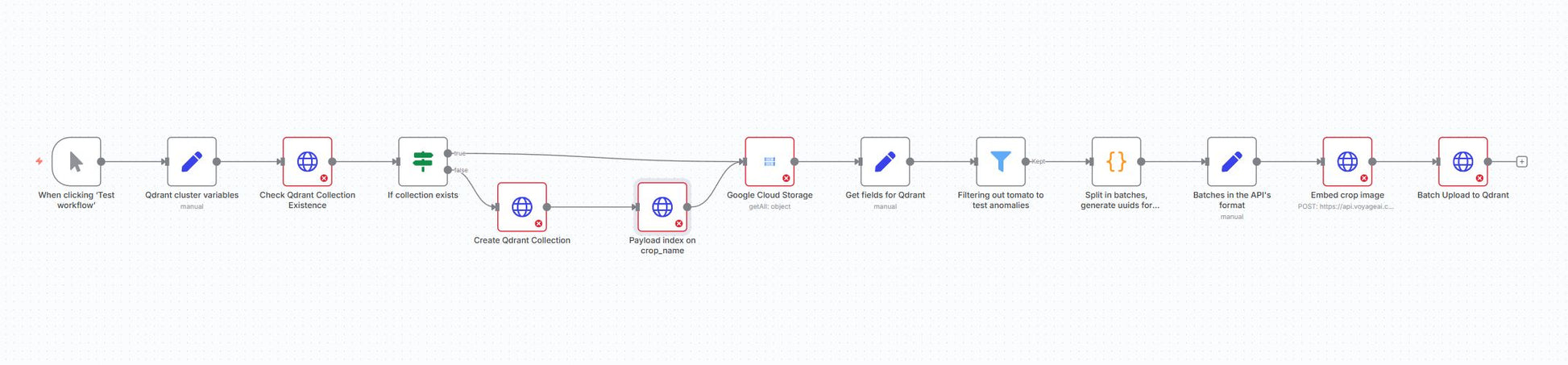
This automation is a production-grade ingestion pipeline that turns raw image datasets into searchable vectors inside Qdrant. It reads images from Google Cloud Storage, constructs public-safe URLs, generates multimodal embeddings with Voyage AI in controllable batches, and bulk-upserts the vectors plus payload metadata into a Qdrant collection. The workflow also provisions the collection (named vectors, vector size, metric), establishes a payload index for fast filtering on crop_name, filters out specified classes for anomaly experiments, and guarantees stable IDs per point via UUIDs.
How it works
-
Bootstrap & checks: Define cluster variables (cloud URL, collection name, embedding dimension, batch size), check if the target collection exists, and create it if missing with named vectors and cosine similarity.
-
Indexing for speed: Create a payload index on
crop_nameto enable efficient filtered queries later. -
Source import: List dataset objects from Google Cloud Storage with a path prefix; derive a public link and the class label from the folder structure.
-
Curation & batching: Optionally exclude certain classes (e.g., tomatoes for anomaly tests), split into batches, and generate UUIDs for deterministic point IDs.
-
Embeddings: Call Voyage AI’s multimodal embedding endpoint with the image URLs in batch format.
-
Vector upsert: Upload vectors and payloads to Qdrant in batch using the prepared IDs.
Why it’s a game-changer
-
From files to vectors, automatically: No manual pre-processing scripts, CSV staging, or brittle one-offs.
-
High throughput with control: Batch sizing, UUIDs, and named vectors keep imports fast and reproducible.
-
Query-ready structure: Payload indexing and consistent labels enable downstream anomaly detection, KNN classification, and semantic search immediately.
-
Adaptable to any image dataset: Swap the storage prefix, labels, and filter rules without re-architecting.
Ideal for AI/ML teams, data engineers, and platform groups standing up vector search, anomaly detection, or image classification workloads on Qdrant.
Manually stitching storage listing, URL normalization, batching, embedding calls, index creation, and robust upserts into a reliable, restartable pipeline can consume several engineer-weeks and still risk edge-case failures. This build consolidates that effort with: collection provisioning, payload indexing, dataset curation, UUID-stable IDs, batched multimodal embeddings, and bulk point upserts. For teams ingesting tens of thousands of images, this saves weeks of build time and hundreds of engineer-hours while reducing mis-ingest risk and enabling faster time-to-value on search, detection, and classification use cases.